






TL;DR
- URI를 UTF-8 형식으로 인코딩 한다.
- 라우터가 URI를 해석할 수 있는지 확인한다.
- 예를 들어, 아래 URI 처럼 "원피스(만화)/조·홀케이크 아일랜드 편"이 파라미터로 사용되어야 할 때
-
상황 1. 서버에 특수 기호가 포함된 URI를 사용해 요청을 보내고 있다면
GET /api/:keyword- URI에서
:keyword에 해당되는 부분을encodeURIComonent()함수로 인코딩한다.const response = await axios.get(`/${encodeURIComponent(keyword)}`); encodeURI()- URI 식별에 필요한 특수기호를 인코딩하지 않음
- URI 문자열 전체를 인코딩하기에 적합
encodeURIComponent()- URI 식별에 필요한 특수기호까지 인코딩 함
- URI의 일부를 구성하는 한 컴포넌트를 인코딩하기에 적합
- URI에서
-
상황 2. URI 라우팅을 SPA의 네비게이션 기능에 사용하고 있다면
- https://blog.anteater-lab.link/namu-soup/m/원피스(만화)/조·홀케이크 아일랜드 편%2F%EC%A1%B0%C2%B7%ED%99%80%EC%BC%80%EC%9D%B4%ED%81%AC%20%EC%95%84%EC%9D%BC%EB%9E%9C%EB%93%9C%20%ED%8E%B8)
- URI를 인코딩하는 것에 더해 라우터가 해당 파라미터를 해석할 수 있도록 해야한다.
- 라우터 구현 방식 혹은 사용한 라우터 라이브러리에 따라 방법이 달라진다.
- 필자는 React Router v6을 사용 중이었고, splats를 사용했다.
// 라우트 정의 <Route path="/m/*" element={<MemoList />} />// 파라미터 사용 const { "*": splat } = useParams();
-
이하 그리 중요하진 않은 내용들
바쁜 현대사회, 가끔씩은 나무 대신 숲을 봐야 할 때도 있습니다.
잠시 광고
블로그 글은 뜨문뜨문 쓰고 있지만, 나름 매일 이것저것 만들어보면서 살고 있다. 숲 - 나무위키 인기 검색어는 위의 표어에서 시작해 간단하게 만들어본 사이트다. 어떤 사이트인지는 깃허브 저장소의 문서를 참고하시라. 이번 글에서는 이 사이트를 만들면서 겪은 문제에 대해 정리하려 한다.
URI(Uniform Resource Identifier)
통합 자원 식별자(Uniform Resource Identifier, URI)는 인터넷에 있는 자원을 나타내는 유일한 주소이다. - 통합 자원 식별자, 위키피디아
URI 혹은 URL 혹은 웹 주소. 웹 서비스를 개발 하면 URI를 자주 마주친다. 전설적인 팀 버너스리가 제시한 이 표시법을 사용해 우리는 웹에서 요청을 어디로 보내야 할 지 특정할 수 있다. URI는 다음 문법으로 정의된다. 자세한 정의는 여기서 확인하자.
URI = scheme ":" ["//" authority] path ["?" query] ["#" fragment]이처럼 URI에는 특수한 목적의 문자들이 사용된다. 예를 들어 위 문법에서 path는 / 기호를 사용해 경로를 구분한다. 그렇다면 만약 아래와 같은 URI가 주어지면 브라우저는 어떻게 URI를 해석할까?
https://soup.anteater-lab.link/api/원피스(만화)/조·홀케이크 아일랜드 편
(내 백엔드 서버가 아직 살아있다는 가정 하에) 위 주소를 그대로 복사해 주소창에 붙여넣으면 해당 경로에 GET 요청을 보낼 수 없다는 페이지를 만날 것이다. 왜냐하면 내 서버의 API는 /api/:keyword 형태로 열려 있어서 원피스(만화)/조·홀케이크 아일랜드 편 전체를 경로의 마지막 요소로 사용해야 하기 때문이다.
인코딩

하지만 http: 옆에 슬래시를 두 개 적도록 한것 말고는 설계에 실수가 없었다는 팀 버너스리의 말처럼 URI는 이미 해결책을 가지고 있다. URI의 제안서는 UTF-8과 같은 인코딩을 사용해 URI를 식별하는 방안을 소개한다. UTF-8을 사용하는 방식은 널리 사용되고 있으며, 예시로 올린 경로를 주소창에 붙여넣었을 때에도 위의 사진 처럼 브라우저가 알아서 해당 URI를 인코딩하는 것을 확인할 수 있다.
- 원 : %EC%9B%90 / 피 : %ED%94%BC / 스 : %EC%8A%A4
URI를 UTF-8 방식으로 인코딩 하면 된다. 따라서 이 경로를 들어가면 제대로 된 응답을 받을 수 있을 것이다. (물론 여전히 응답 코드는 404일 테지만)
하지만 / 까지 브라우저가 자동으로 인코딩해주진 않는다. 주소에서 api 뒤에 있는 슬래시를 경로 구분자로 봐야 할지 자원 이름의 일부로 봐야 할지 브라우저는 판단할 수 없기 때문이다. URI에 반드시 필요한 특수기호들 까지 브라우저가 알아서 인코딩 해줄순 없다. 이제 개발자의 간단한 수고가 필요한 순간이다. Javascript의 내장 함수 encodeURIComponent()를 쓰자. 인코딩 함수의 결과를 필요에 따라 <a> 태그의 href 속성으로 달아주거나, AJAX 요청의 인수로 사용하면 된다.
encodeURIComponent("원피스(만화)/조·홀케이크 아일랜드 편");
// "%EC%9B%90%ED%94%BC%EC%8A%A4(%EB%A7%8C%ED%99%94)%2F%EC%A1%B0%C2%B7%ED%99%80%EC%BC%80%EC%9D%B4%ED%81%AC%20%EC%95%84%EC%9D%BC%EB%9E%9C%EB%93%9C%20%ED%8E%B8"
// "/" => "%2F"
const targetURI = "https://soup.anteater-lab.link/api/"
+ encodeURIComponent("원피스(만화)/조·홀케이크 아일랜드 편");대신 주의할 점 하나, encodeURI()라는 내장 함수도 존재한다. 이 함수는 브라우저가 알아서 URI를 인코딩하는 것과 같은 동작을 한다. /와 같은 특수기호를 인코딩하지 못한다. 둘을 비교하자면 다음과 같다.
encodeURI()- URI 식별에 필요한 특수기호를 인코딩하지 않음
- URI 문자열 전체를 인코딩하기에 적합
encodeURIComponent()- URI 식별에 필요한 특수기호까지 인코딩 함
- URI의 일부를 구성하는 한 컴포넌트를 인코딩하기에 적합
서버에 요청을 보내는게 아니라면?
약간 더 복잡한 문제로 넘어가보자. 최근엔 프론트엔드 한다면 다들 SPA(Single Page Application) 프레임워크를 하나 이상 다루는 것을 기본 소양으로 삼을 것이다. SPA에서 화면 전환의 핵심 아이디어는 페이지 전체를 다시 로드하지 않고 필요한 부분만 변경시키는 것이다. 이를 구현하는 방식은 다양하지만, 대표적인 방식으로 PJAX(history.pushState())를 사용한 CSR, Client-side Rendering(Routing)이 있다. CSR은 서버에게 새 요소를 랜더링해 달라고 요청을 보내지 않고 클라이언트(웹 어플리케이션)가 직접 화면 요소를 변경시키는 방식이다. 이때 PJAX로 변경된 URI를 파싱해 어떤 화면 요소를 그릴지 선택한다. 화면 요소를 그린다는 점에서 Rendering이고 URI를 해석해 경로를 결정한단 점에서 Routing인 것이다.
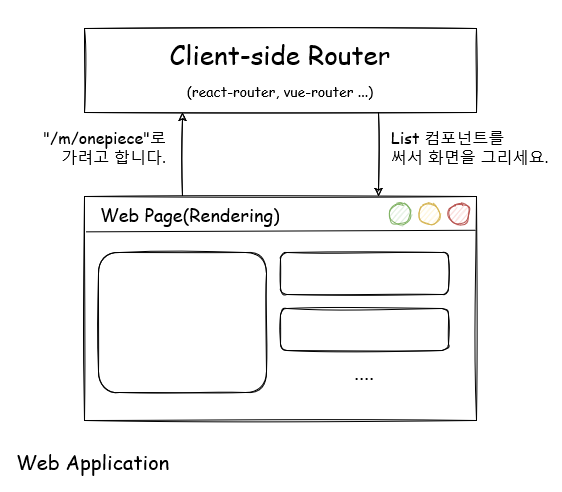
이제 우리는 클라이언트에서도 라우터 모듈이 필요해졌다. 직접 바닐라 Javascript로 구현해도 말릴 사람은 없지만 일반적으론 사용 중인 프레임워크에 최적화된 라이브러리를 사용한다. 나는 최근엔 React로 개발을 하다 보니 React Router를 자주 사용 한다.
// App.jsx
// 라우트 정의
<Routes>
<Route path="/m/:keyword" element={<MemoList />} />
</Routes>// TrendingList.jsx
// 라우팅
<Link to={`/m/${keyword}`}>
메모 화면으로 이동
</Link>// MemoList.jsx
// 파라미터 사용
const { keyword } = useParams();클라이언트 라우터에서도 똑같이 특수문자가 포함된 URI는 문제가 될 수 있다. 그럼 똑같이 <Link/>의 keyword를 encodeURIComponent()로 변환해주면 문제가 해결될까? 하지만 함정이 있으니, 클라이언트에 있는 React Router가 URI를 해석하기 위해 decodeURIComponent() 함수를 사용한다(심지어 손수 에러 처리까지 구현해 안전한 함수로 포장해서). 무슨 말이냐 하면, 어차피 keyword를 인코딩해서 라우터 모듈에 보낸다 하더라도 라우터는 URI를 특수 문자가 포함된 문자열로 인식하게 된다는 뜻이다.
Splats

근데 "*"을 splat이라고도 부르는줄은 몰랐네
React Router에선 해당 문제를 해결하기 위해 Splats이라는 기능을 제공한다. 이름은 생소한데, "*" 이 기호를 뜻한다. 일명 와일드카드 혹은 Catch All. 흔히 사용되는 의미와 똑같다. 라우트 정의 단계에서 필요한 경로 끝에 붙여 뒤에 오는 문자열을 모두 받아 쓰겠다고 정의한다.
// 라우트 정의
<Route path="/m/*" element={<MemoList />} />// 파라미터 사용
const { "*": splat } = useParams();이건 React Router의 해결법이고, 각자 사용한 라이브러리에 따라 이런 문제를 해결하는 방법을 제공할 것이다. 혹은 본인이 직접 라우터를 구현했으면, 이런 글을 찾아볼 필요도 없는 실력을 가졌겠지만, 라우터 모듈이 경로를 원하는 대로 해석할 수 있도록 규칙을 수정해주면 된다. 요점은, 내 프로그램에서 문제가 발생하는 곳이 어디인지 정확히 짚어야 한다는 것이다.
내가 배운 것
엄청 복잡한 문제는 아니었다. 정말 "자잘한"에 어울리는 주제가 아니었나 싶다. URI 인코딩 보다는 웹 페이지의 렌더링과 라우팅에 대해 다시 생각해볼 수 있는 기회가 되었던 것 같다.
- "*"을 splat이라고 부르는 사람도 있나보다.
- 팀 버너스리가 WWW 만들면서 URL도 만들었다. 대단한 사람...
- SPA에서 라우팅은 다양한 방식으로 구현할 수 있다.
history.pushState()API를 활용하는 방식을 PJAX라고 부르는데
메이저한 명명법은 아닌 것 같다.- Next.js는 React Router와 경쟁하는 관계다.
- 프론트엔드의 라우터는 백엔드의 라우터와 역할상 크게 다르지 않다.
- 문제가 발생하는 곳이 어디인지 정확히 짚어야 한다.
